栏目分类
你的位置:开云·kaiyun(全站)体育官方网站/网页版 登录入口 > 资讯 > 开yun体育网因为作家为每个任务采样了好多反应-开云·kaiyun(全站)体育官方网站/网页版 登录入口
开yun体育网因为作家为每个任务采样了好多反应-开云·kaiyun(全站)体育官方网站/网页版 登录入口
发布日期:2025-04-16 10:12 点击次数:234

编订:桃子 好困
32B小模子在超硬核「期间萍踪」推理谜题中,一举打败了o1、o3-mini、DeepSeek-R1,中枢普遍火器就是GRPO,最关节的是老师资本暴降100倍。
用上DeepSeek核默算法,也能打败R1。
在具有挑战性的「期间萍踪」(Temporal Clue)逻辑谜题中,基于强化学习微调后的Qwen 2.5 32B,推理武艺皆备碾压o1、o3-mini、R1。
以致,它还追平了Claude 3.7 Sonnet,通盘模子推理资本暴降100多倍!
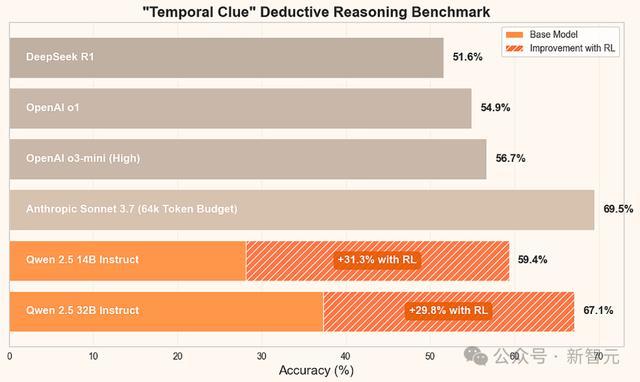
「期间萍踪」逻辑谜题脱胎于经典桌游Clue,并加入了when、why的两个全新维度,号称逻辑推理的「珠穆朗玛峰」。
它不仅能磨真金不怕火模子基本推理武艺,更爆料顶级大模子软肋。
对此,前谷歌工程师,初创OpenPipe联创Kyle Corbitt和团队将其行动模子的「终极试真金不怕火场」,提议了一个果敢的假定——
小模子在复杂推理任务中,能否逆袭,达到或超过顶尖LLM?
他们采用开源的Qwen模子(14B和32B),通过GRPO强化学习,对其进行了妖怪式老师。
如前所见,这些小模子的推感性能,得到了显赫提高。
但轰动远不啻于此,团队还发现了一些奇怪的惬心:Qwen 14B的推理长度随期间「偶然」增多,而Qwen 32B的推理长度却在减少。
而且,这一切竟发生在奖励机制皆备不触及长度的情况下。
传统不雅念以为,唯一参数目迷漫大的LLM,武艺称霸推理任务。
但这个最新解说,即就是14B/32B小而精的模子,用上奥密的优化战略——GRPO,不异能站上巅峰。
网友挑剔区追问,QWQ 32B也有用吗?
Kyle折服谈,那是一定的,它与Qwen 2.5 32B选拔了归拢个架构。
AI推理新战场:期间萍踪
前年,OpenAI推出划期间o系列推理模子以来,在AI界掀翻了一场强化学习(RL)的怒潮。
谷歌DeepMind、阿里、DeepSeek、Anthropic等巨头纷纷入局,打造出进行长链式想维(CoT)推理的高级模子。
好多以往具有挑战性的基准测试——如数学和编码限制——如今已接近饱和。
关联词,即就是如今最顶尖模子,面临逻辑推理这块硬骨头,也常常会犯初级伪善。
为此,OpenPipe两位联创决定挑战这个未解之谜——用RL微调后的小模子,去挑战复杂推理题。
基准测试
为此,护士东谈主员基于桌游Clue,打造了一个新基准——期间萍踪,将其改动为一个单东谈主逻辑谜题,超过了传统维度(who、what、where)。
这些谜题通过OR-Tools 的 CP-SAT 求解器偶然生成,并挑选出最精简,却致命的萍踪:
在一个阴凉的冬夜,富饶且普遍的John Q. Boddy先生为几位亲密伙伴举办了一场袖珍但阔绰的晚宴。关联词,夜晚以悲催完毕——早晨,Boddy先生被发现死在都铎庄园的某个房间内。以下为涉案嫌疑东谈主名单…
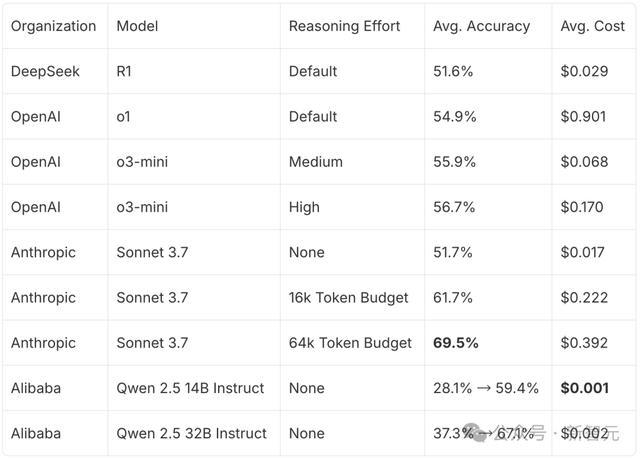
把子有了之后,护士东谈主员先对顶尖大模子进行了测试,包括DeepSeek-R1、o1、o3-mini,以及Claude Sonnet 3.7,以及开源的Qwen 14B和32B。
末端如下图所示,有64k token想考预算的Claude Sonnet 3.7,弘扬最优。
开源DeepSeek-R1险些与o1、o3-mini性能格外。关联词,未经调优的Qwen 2.5 Instruct模子弘扬平平。
那么,怎样将这些较小的开源模子老师到前沿水平?
小模子逆袭诀要:GRPO
谜底就是,强化学习——允许智能体在受控环境中从自己申饬中学习。
这里,LLM是智能体,而谜题则是环境。
护士东谈主员通过让LLM为每个谜题生成多个反应来携带它们的学习,探索问题的空间。而况,强化那些导向正确谜底的推理,并对导致模子偏离正确旅途的推理进行处分。
在多种RL治安中,他们弃取了由DeepSeek设备的流行的GRPO算法。与传统的PPO等治安比较,GRPO简化了老师经由,同期仍能提供宽广的性能。
为了加快本质,团队不祥了Kullback-Leibler(KL)散度处分。
从高等次来看,模子的老师轮回衔命以下基本治安:
生成模子对谜题任务的反应
对反应进行评分,并推断每组对话完成的上风(这是GRPO中「分组相对比较」的部分)
使用由这些上风推断指导的剪辑战略梯度对模子进行微调
使用新的谜题和最新版块的模子肖似这些治安,直到达到峰值性能
在生成反适时,护士东谈主员使用了流行的vLLM推理引擎,通过诊治了参数弃取,以最大化综合量并最小化启动期间。
Prefix caching尤为遑急,因为作家为每个任务采样了好多反应,缓存辅导有助于幸免冗余算计。
他们不雅察到,向vLLM发送过多央求,会导致正在进行中的央求被霸占或交换。
为了搞定这个问题,他们使用信号量(semaphore)截止央求,以保抓高KV缓存诈欺率,同期最小化交换。
更高级的诊治机制可能会在援助天真生成长度的同期,进一步提高诈欺率。
在采样后,护士东谈主员使用法度的HuggingFace Transformers AutoTokenizer处理完成本色。
其聊天模板功能将音信对象渲染为辅导字符串,并包含一个助手掩码(assistant mask),用于细目LLM生成的token。
他们发现模子的默许模板中,穷乏必要的「% generation %」标签 ,因此在分词治安中对其进行了修改。
生成的助手掩码被包含在用于微调的张量字典中,以识别哪些位置需要算计耗费。
在分词反应并获取助手掩码后,护士东谈主员对数据进行打包以进行微调。除了在每个打包序列中包含多个辅导/响吩咐外,咱们还识别了分享的辅导token,并为每个token分拨了一个Parent ID,以及Group ID。
格外是关于像「期间萍踪」这么的任务——每个谜题平均逾越1,000个token——为每个任务生成大都反应并高效打包张量显赫减少了冗余。
一朝打包了扫数必要信息,便不错将老师数据集可视化为2D面容,每一转都是一个token序列,可能包含多个辅导和完成本色:
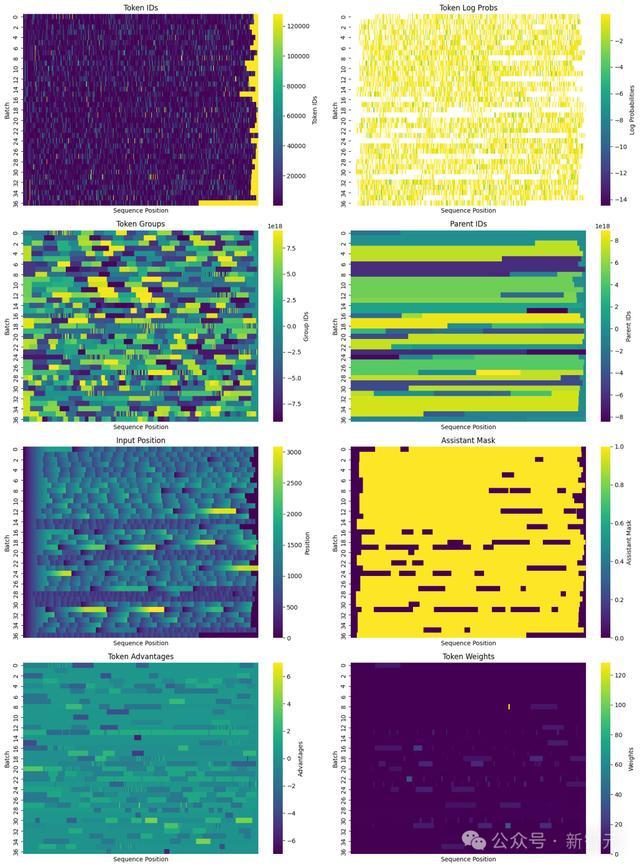
有了致密打包的数据后,就不错运行微调了。
Qwen模子依然经过了预老师和指示微调,具备格外的智能水平,而况擅长衔命指示。
关联词,它们还无法可靠地搞定「期间萍踪」谜题。尽管如斯,它们偶尔也能成功,而这依然迷漫了。
通过增多精良推理的概率并减少「不良」推理的概率,护士东谈主员迟缓将模子携带至「侦查民众」级的水平。
他们使用法度的机器学习本领已毕了这少量,选拔战略梯度治安算计耗费并故意地诊治权重。
在老师经由中,他们使用了PyTorch团队提供的torchtune库。Torchtune为包括Llama、Gemma、Phi等流行模子提供了高效的仅解码器(decoder-only)Transformer已毕。
诚然在这个神态中,他们主要使用了Qwen模子,但也对8B和70B的Llama模子进行了本质。
Torchtune还提供了检朴内存和提高性能的用具,包括:
激活查验点(Activation Checkpointing)
激活卸载(Activation Offloading)
量化(Quantization)
参数高效微调(PEFT),举例低秩适合(LoRA)
此外,Torchtune援助多设备(以及当今的多节点)老师,使其相配恰当更大的模子。它援助全分片数据并行(FSDP)和张量并行(TP)老师,而况不错集结使用。
他们还提供了十几种老师recipes,饱读吹用户复制并字据我方的用例进行定制。护士东谈主员在此创建了一个修改版的完好微调配方,援助以下功能:
多设备和单设备老师
参考模子加载和权重交换,用于算计KL散度
使用组ID和父ID进行高级因果掩码算计
GRPO耗费集成和组件日记纪录
改日,他们但愿添加张量并行援助,并探索PEFT和量化。
RL老师经由触及弃取大都的超参数。在老师模子时,护士东谈主员测试了多样设立,并最终细目了以下设立:
模子:Qwen 2.5 Instruct 14B和32B
每次迭代的任务数:32
每次迭代每个任务的样本数:50
每次迭代的总样本数:32*50=1600
学习率:6e-6
Micro-Batch大小:14B模子为4个序列,32B模子为8个序列
批大小:可变,取决于序列数目
批大小是可变的,因为在老师经由中反应长度可能会变化,序列打包成果每次迭代都会波动,而况上风为零的反应会被丢弃。
在一次本质中,护士东谈主员尝试了动态诊治学习率,使其与批大小成反比,但这导致小批大小的学习率过高,需要设立上限。
设立上限后的版块与使用恒定学习率莫得显赫各异,但诊治批大小和学习率仍然是改日本质的一个好奇好奇标的。
此外,护士东谈主员还进行了苟简的本质,增多每次迭代的任务数同期减少每个任务的样本数,反之也是,保抓每次迭代的总样本数八成交流。
在较短的老师期间内,这些变化莫得披浮现显赫各异,标明配方对任务数和每个任务的样本数之间的不同均衡具有鲁棒性。
100次迭代,已毕SOTA
末端披露,模子在阅历逾越100次迭代老师后,已毕了SOTA级的演绎推理武艺。
从下图中不错看到,模子的性能在老师初期飞快提高,并在之后缓缓放缓;关联词到了末期,准确率却运行出现退化,以致急剧下跌。
在最好情景下,14B模子在16k tokens的落魄文窗口下接近Claude Sonnet 3.7的性能,而32B模子在更大的64k落魄文容量下险些匹配了Sonnet的末端。
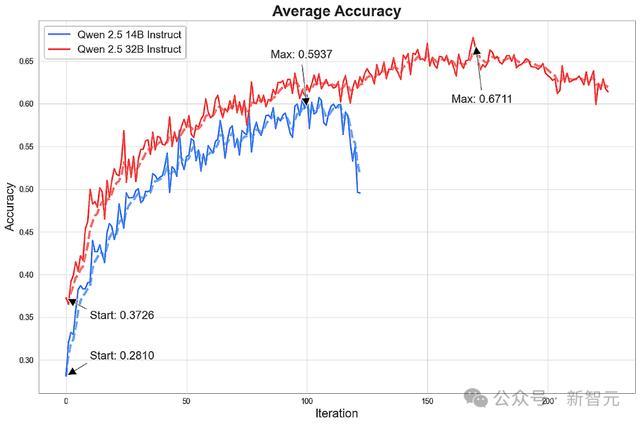
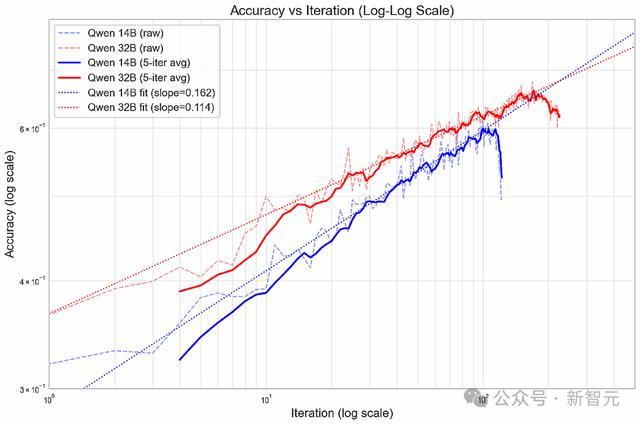
老师经由中,性能提高衔命幂律散布,在对数-对数坐标图上呈现线性联系(在性能运行下跌之前)。
护士东谈主员推测,之是以出现这种惬心,有可能是因为模子过早地拘谨于初期就有用的贪心战略,从而截止了弥远的发展后劲。
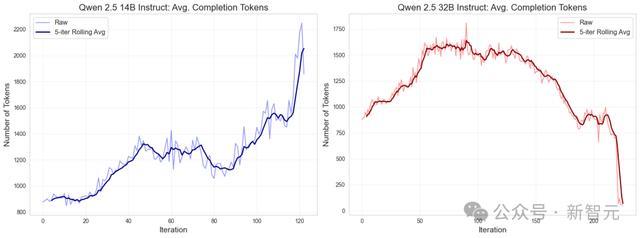
此外,还不错不雅察到,输出的长度在老师期间也呈现出了一种好奇好奇的变化方式。
刚运行的时候反应长度会迟缓增多,然后趋于认知;而在老师后期,则出现了显着的分化惬心——14B模子的反应变得更长,而32B模子的反应长度显赫减少,格外是在达到峰值性能后。
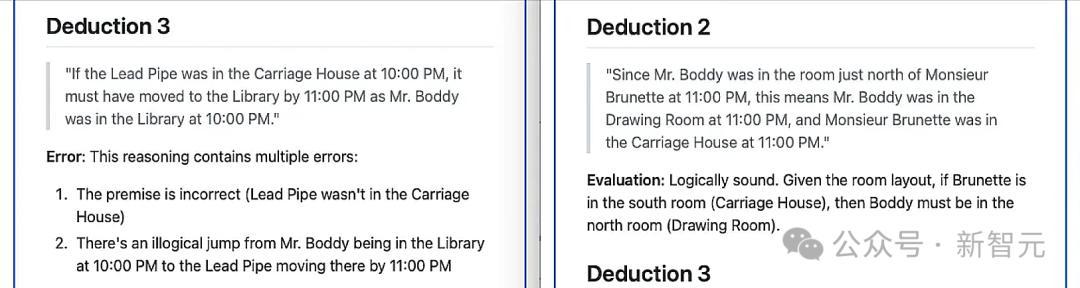
为了定性评估逻辑推理武艺的提高,团队决定使用最新的Claude Sonnet 3.7来对Qwen 32B模子的解谜推理武艺进行分析。
在未经老师的基础模子中,Sonnet识别出了6个推表面断,其中5个被判定为伪善
在经过100屡次迭代老师后的模子中,Sonnet识别出了7个推表面断,其中6个被判定为稳妥逻辑
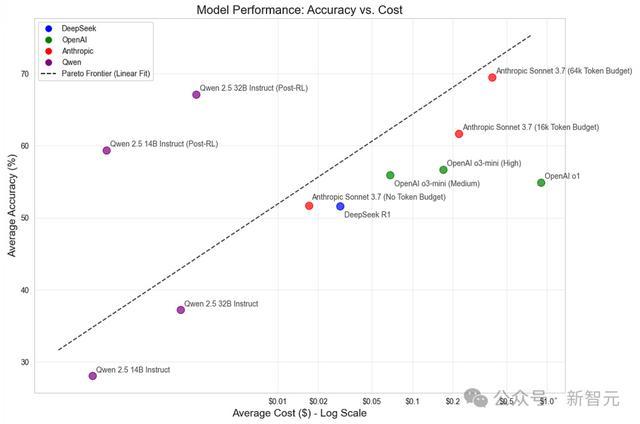
接下来,团队字据Fireworks AI的无就业器订价决策估算了Qwen模子的资本。(假定能得回迷漫的算计综合量)
通过将准确率与每个反应平均推理资本的当然对数进行对比,团队发现,莫得经过微调的模子存在着显着的线性帕累托最优前沿(示意在这条弧线上,无法同期提高准确率和缩短资本)。
而团队提议的治安,不仅将开源模子老师到了SOTA级的准确率,而且还极地面改善了资本与准确率之间的衡量联系。
值得一提的是,团队还在临了为寰宇留了一个格外令东谈主旺盛的发现——仅使用16个老师样例就能已毕高达10-15%的显赫性能提高。
这意味着,不需要大都数据即可运行,设备者只需对我方想搞定的问题有一些基本的直观意志即可。
在著述的临了,团队写谈:
跟着责任的圆满完成开yun体育网,咱们互相相视一笑,立时叫了一辆双轮马车复返贝克街——这里恰是复盘「案情」的绝佳局势。
